Vision Transformer
2021 年,谷歌发布了 Vision Transformer(ViT),ViT 是第一个完全在计算机视觉领域使用 Transformer 结构的模型,ViT 首先应用在图像分类任务上,取得了不错的结果,例如:在 ImageNet 2012 数据集上取得了 88.55% 的验证精度、在 CIFAR-100 上取得了 94.55% 的验证精度。
自 2017 年谷歌发布 Transformer 模型之后,在自然语言处理(Natural Language Processing)领域中,主流的模型从递归神经网络(Recurrent Neural Networks)逐渐进化为了 Transformer 模型。由于 Transformer 结构在 NLP 领域的巨大成功,研究者开始将 Transformer 迁移到计算机视觉领域,视觉模型开始引入注意力机制等 Transformer 的核心组件,但视觉模型无法完全脱离卷积神经网络(Convolutional Neural Networks)的架构。
由于注意力机制的时间复杂度与 token 数量成平方关系,如果之间将图片的每一个像素当作一个 token,那么对于高分辨率的图像,就会产生很多的视觉 token,例如,分辨率为 224x224 的图片就会产生 5 万多个 tokens,正因为这个原因,导致我们不能直接将 Transformer 应用到视觉领域,用于目标检测领域的 Transformer 的模型 DETR,采用 CNN 作为图像的编码器,通过卷积和池化,逐渐降低图像的空间维度,有效地降低了视觉 token 的数量。
ViT 给出了一种解决方案,可以完全丢弃卷积神经网络结构。
方法
ViT 的模型结构如下图所示,基本上与原始的 Transformer 结构保持一致,由于 ViT 的目标是完成图像分类任务,因此只需要对图像进行编码即可,所以 ViT 仅使用了 Transformer 编码器。

注意:ViT 使用的 Transformer 编码器块与原始的 Transformer 结构上存在区别,即层归一化(LayerNorm)位于多头注意力层和前馈神经网络层之前。实际上,LN 位于前面还是后面都可以。
ViT 的核心思想是:将输入图像切分成相同大小的 patch,直接对每一个 patch 进行线性投影,就可以得到 patch embedding,相当于进行了图像的分词(tokenization)操作,经过这样的切分和投影后就得到了一系列的视觉 token。此外,类似于 BERT,ViT 还附加了一个 [cls] token,[cls] token 的作用可以理解为总结 token,即对整个序列的总结,在 BERT 中就是对整句话的总结,在 ViT 中就是对整个图像的总结。ViT 在经过 Transformer 编码后,直接将 [cls] token 通过一个 MLP 分类头,从而获取一个概率分布。整个过程可以由以下数学表达式给出:
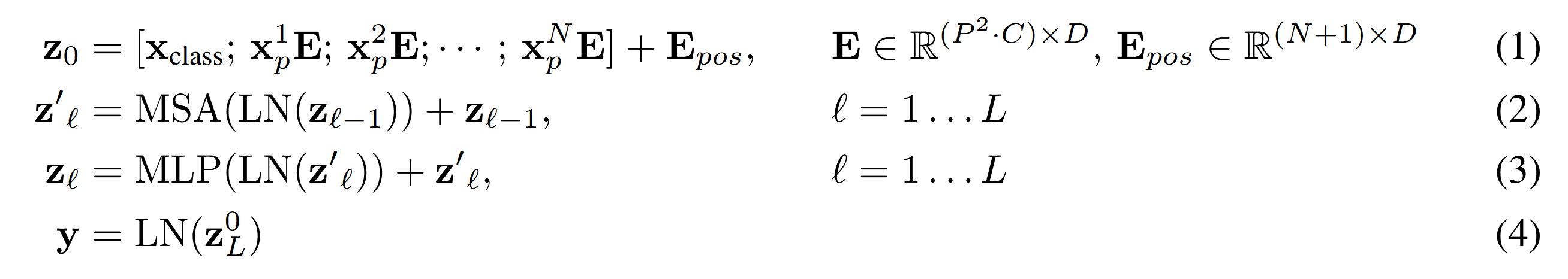
由于 Transformer 使用的注意力机制的特性,注意力的计算对于 token 的顺序是无关的,因此需要添加 token 的位置信息。与原始 Transformer 不同,ViT 使用了可学习的位置编码。同时对于 image patch 的位置采用了一维的编码,即 0、1、2 等等,依次类推,虽然破坏了图像的空间位置信息,但是作者通过实验发现,二维位置编码没有带来显著的性能提升,因此选择了更简单的一维位置编码。
相对于 CNN,ViT 缺乏图像相关的归纳偏置(inductive bias),例如平移不变性、局部性。然而,只要在足够大的数据集上进行训练,就能解决这个问题。
ViT 发布了三组模型参数,遵循了 BERT 的命名方式,如下表所示:
| 模型名称 | 层数 | 隐藏层维度 | MLP 维度 | 注意力头数量 | 参数量 |
|---|---|---|---|---|---|
| ViT-Base | 12 | 768 | 3072 | 12 | 86M |
| ViT-Large | 24 | 1024 | 4096 | 16 | 307M |
| ViT-Huge | 32 | 1280 | 5120 | 16 | 632M |
Pytorch 实现
下面是 ViT 的 PyTorch 实现代码,仅供参考。
from typing import Optional, Tuple, Union
import torch
from torch import nn
class VisionTransformer(nn.Module):
"""Vision Transformer"""
def __init__(
self,
image_size: Union[int, Tuple[int, int]],
patch_size: Union[int, Tuple[int, int]],
n_classes: int,
hidden_size: int,
n_heads: int,
ffn_hidden_size: int,
n_layers: int,
n_channels: int = 3,
dropout: float = 0.0,
emb_dropout: float = 0.0,
):
super(VisionTransformer, self).__init__()
self.cls_token = nn.Parameter(torch.randn(1, 1, hidden_size))
self.emb = ViTEmbedding(
hidden_size, image_size, patch_size, n_channels, emb_dropout
)
self.encoder = TransformerEncoder(
n_layers, hidden_size, ffn_hidden_size, n_heads, dropout
)
self.mlp_head = nn.Linear(hidden_size, n_classes)
def forward(self, x: torch.Tensor) -> torch.Tensor:
out = self.emb(x, self.cls_token)
out, attns = self.encoder(out, None)
# obtain output embedding of [cls] token
out = out[:, 0, :]
out = self.mlp_head(out)
return out, attns
class TransformerEncoder(nn.Module):
"""Transformer Encoder."""
def __init__(
self,
n_layers: int,
hidden_size: int,
ffn_hidden_size: int,
n_heads: int,
dropout: float = 0.0,
) -> None:
super(TransformerEncoder, self).__init__()
self.encoder = nn.ModuleList(
[
TransformerEncoderLayer(hidden_size, ffn_hidden_size, n_heads, dropout)
for _ in range(n_layers)
]
)
def forward(
self, x: torch.Tensor, attn_mask: Optional[torch.Tensor]
) -> Tuple[torch.Tensor, Tuple[torch.Tensor, ...]]:
attns = ()
for encoder_layer in self.encoder:
x, attn = encoder_layer(x, attn_mask)
attns += (attn,)
return x, attns
class TransformerEncoderLayer(nn.Module):
"""Transformer Encoder Layer."""
def __init__(
self, hidden_size: int, ffn_hidden_size: int, n_head: int, dropout: float = 0.0
) -> None:
super(TransformerEncoderLayer, self).__init__()
self.attn = MultiHeadAttention(hidden_size, n_head)
self.ffn = MLP(hidden_size, ffn_hidden_size, dropout)
self.norm1 = nn.LayerNorm(hidden_size)
self.norm2 = nn.LayerNorm(hidden_size)
self.dropout1 = nn.Dropout(dropout)
self.dropout2 = nn.Dropout(dropout)
def forward(
self, x: torch.Tensor, attn_mask: Optional[torch.Tensor] = None
) -> Tuple[torch.Tensor, torch.Tensor]:
residual = x
out = self.norm1(x)
out, attn = self.attn(out, out, out, attn_mask)
out = residual + self.dropout1(out)
residual = out
out = self.norm2(out)
out = self.ffn(out)
out = residual + self.dropout2(out)
return out, attn
class MultiHeadAttention(nn.Module):
"""Multi-Head Attention"""
def __init__(self, d_model: int, n_head: int) -> None:
super(MultiHeadAttention, self).__init__()
self.attention = ScaledDotProductAttention()
self.d_model = d_model
self.n_head = n_head
self.d_head = d_model // n_head
self.q_proj = nn.Linear(d_model, d_model)
self.k_proj = nn.Linear(d_model, d_model)
self.v_proj = nn.Linear(d_model, d_model)
self.o_proj = nn.Linear(d_model, d_model)
def forward(
self,
q: torch.Tensor,
k: torch.Tensor,
v: torch.Tensor,
attn_mask: Optional[torch.Tensor] = None,
) -> Tuple[torch.Tensor, torch.Tensor]:
# 1. linear projection
q, k, v = self.q_proj(q), self.k_proj(k), self.v_proj(v)
# 2. split tensor by number of heads
q, k, v = self._split(q), self._split(k), self._split(v)
# 2. apply scaled dot product attention
out, attn = self.attention(q, k, v, attn_mask)
# 3. concat tensor
out = self._concat(out)
# 4. output projection
out = self.o_proj(out)
return out, attn
def _split(self, tensor: torch.Tensor) -> torch.Tensor:
bsz, seq_len, _ = tensor.shape
return tensor.view(bsz, seq_len, self.n_head, self.d_head).transpose(1, 2)
def _concat(self, tensor: torch.Tensor) -> torch.Tensor:
bsz, _, seq_len, _ = tensor.shape
return tensor.transpose(1, 2).contiguous().view(bsz, seq_len, self.d_model)
class ScaledDotProductAttention(nn.Module):
"""Scaled Dot Product Attention."""
def __init__(self) -> None:
super(ScaledDotProductAttention, self).__init__()
self.softmax = nn.Softmax(dim=-1)
def forward(
self,
q: torch.Tensor,
k: torch.Tensor,
v: torch.Tensor,
attn_mask: Optional[torch.Tensor] = None,
) -> Tuple[torch.Tensor, torch.Tensor]:
"""Apply Scaled Dot Product Attention.
Args:
q (torch.Tensor): query tensor, of shape (batch_size, num_head, tgt_len, head_dim)
k (torch.Tensor): key tensor, of shape (batch_size, num_head, src_len, head_dim)
v (torch.Tensor): value tensor, of shape (batch_size, num_head, src_len, head_dim)
attn_mask (Optional[torch.Tensor]): attention mask, (batch_size, num_head, tgt_len, src_len)
Returns:
Tuple[torch.Tensor, torch.Tensor]: attention outputs, attention weights
"""
# 1. compute attention scores
scale = k.size(-1) ** -0.5
scores = torch.einsum("bntd,bnsd->bnts", q, k) * scale
# 2. apply attention mask (optional)
if attn_mask is not None:
scores += attn_mask
# 3. compute attention weights
attn = self.softmax(scores)
# 4. compute attention outputs
out = torch.einsum("bnts,bnsd->bntd", attn, v)
return out, attn
class MLP(nn.Module):
"""Multi-Layer Perceptron."""
def __init__(
self, hidden_size: int, ffn_hidden_size: int, dropout: float = 0.0
) -> None:
super(MLP, self).__init__()
self.linear1 = nn.Linear(hidden_size, ffn_hidden_size)
self.linear2 = nn.Linear(ffn_hidden_size, hidden_size)
self.gelu = nn.GELU()
self.dropout = nn.Dropout(dropout)
def forward(self, x: torch.Tensor) -> torch.Tensor:
out = self.linear1(x)
out = self.gelu(out)
out = self.dropout(out)
out = self.linear2(out)
return out
class ViTEmbedding(nn.Module):
def __init__(
self,
hidden_size: int,
image_size: Union[int, Tuple[int, int]],
patch_size: Union[int, Tuple[int, int]],
n_channels: int = 3,
dropout: float = 0.0,
) -> None:
super(ViTEmbedding, self).__init__()
self.patch_emb = PatchEmbedding(patch_size, hidden_size, n_channels)
self.pos_emb = PositionEmbedding(hidden_size, image_size, patch_size)
self.dropout = nn.Dropout(dropout)
def forward(self, x: torch.Tensor, cls_token: torch.Tensor) -> torch.Tensor:
"""Apply ViT embedding."""
bsz = x.size(0)
cls_token = cls_token.expand(bsz, -1, -1)
pos_emb = self.pos_emb(x)
patch_emb = self.patch_emb(x)
return self.dropout(pos_emb + torch.cat([cls_token, patch_emb], dim=-2))
class PatchEmbedding(nn.Module):
"""Patch Embedding Layer."""
def __init__(
self,
patch_size: Union[int, Tuple[int, int]],
hidden_size: int,
n_channels: int = 3,
) -> None:
super(PatchEmbedding, self).__init__()
self.patch_size = _pair(patch_size)
self.conv = nn.Conv2d(
n_channels, hidden_size, kernel_size=patch_size, stride=patch_size
)
def forward(self, x: torch.Tensor) -> torch.Tensor:
"""Apply patch embedding."""
return torch.flatten(self.conv(x), start_dim=-2).transpose(-1, -2)
class PositionEmbedding(nn.Module):
"""Position Embedding Layer."""
def __init__(
self,
hidden_size: int,
image_size: Union[int, Tuple[int, int]],
patch_size: Union[int, Tuple[int, int]],
) -> None:
super(PositionEmbedding, self).__init__()
self.image_size = _pair(image_size)
self.patch_size = _pair(patch_size)
self.hidden_size = hidden_size
img_width, img_height = self.image_size
patch_width, patch_height = self.patch_size
if img_width % patch_width != 0 or img_height % patch_height != 0:
raise ValueError(
f"Image dimensions must be divisable by the patch size! But got image size: {self.image_size} and patch size: {self.patch_size}"
)
self.num_patches = (img_width // patch_width) * (img_height // patch_height)
self.pos_emb = nn.Parameter(torch.randn(1, self.num_patches + 1, hidden_size))
def forward(self, x: torch.Tensor) -> torch.Tensor:
"""Apply position embedding"""
width, height = x.shape[-2:]
if (width, height) != self.image_size:
raise AssertionError(
f"Expected image size: {self.image_size}. But got {(width, height)}"
)
return self.pos_emb
def _pair(x: Union[int, Tuple[int, int]]) -> Tuple[int, int]:
return x if isinstance(x, tuple) else (x, x)
参考
[1] A. Dosovitskiy et al., “An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale,” Jun. 03, 2021, arXiv: arXiv:2010.11929. doi: 10.48550/arXiv.2010.11929.
[2] A. Vaswani et al., “Attention is All you Need,” in Advances in Neural Information Processing Systems, Curran Associates, Inc., 2017.
[3] J. Devlin, M.-W. Chang, K. Lee, and K. Toutanova, “BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding,” May 24, 2019, arXiv: arXiv:1810.04805. doi: 10.48550/arXiv.1810.04805.
[4] lucidrains. “vit-pytorch”. Github 2020. [Online]. Available: https://github.com/lucidrains/vit-pytorch
[5] N. Carion, F. Massa, G. Synnaeve, N. Usunier, A. Kirillov, and S. Zagoruyko, “End-to-End Object Detection with Transformers,” May 28, 2020, arXiv: arXiv:2005.12872. doi: 10.48550/arXiv.2005.12872.
文档信息
- 本文作者:Ziyang Fan
- 本文链接:https://fanziyang-v.github.io/2025/03/22/vit/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)