CLIP
CLIP(Contrastive Language-Image Pretraining) 是 OpenAI 在多模态领域中非常经典、且影响力巨大的工作。CLIP 在 4 亿个图像-文本对数据集上进行视觉-文本对齐预训练,在 ImageNet 2012 数据集上的验证精度达到了 76.2 %。由于 CLIP 具有强大的零样本(zero-shot)泛化能力,后来出现了许多 CLIP 相关的工作,例如将 CLIP 应用到图像检索、分割等领域。
方法
下图摘自 CLIP 原始论文的框架图,非常清晰地阐述了 CLIP 的核心思想。
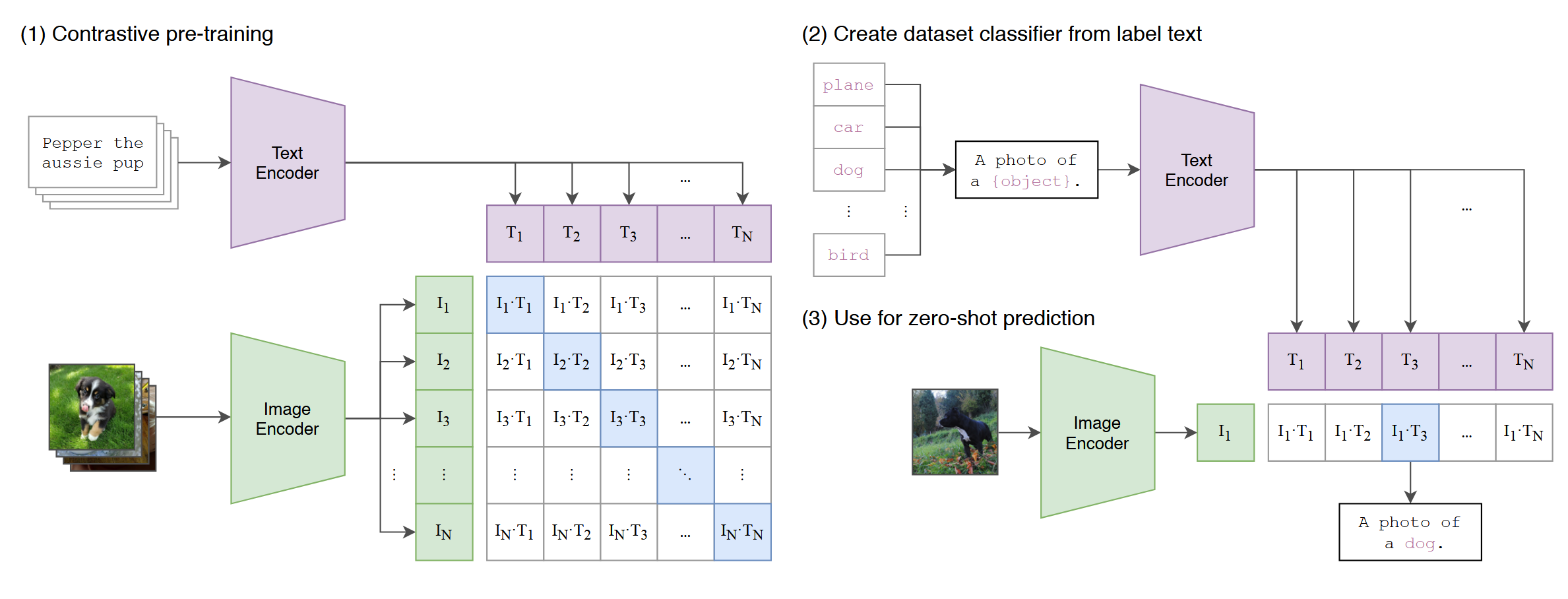
具体而言,CLIP 训练两个模型,分别为视觉编码器、文本编码器,它们分别将图片和文本进行编码,分别得到一个表示图片和文本的向量,利用对比学习(Contrastive Learning)进行图像-文本的对齐训练,尽可能缩小正样本的距离,尽可能扩大负样本的距离。
进行零样本图片分类任务时,将目标数据集的类别通过 “A photo of {Label}” 模板替换,利用 CLIP 的文本编码器进行编码,使用 CLIP 的视觉编码器对目标图片进行编码,直接计算向量之间的余弦相似度,相似度最高的类别即为预测类别。
这里简要介绍一下对比学习,对比学习是一种自监督学习(Self-supervised Learning)的方式,在对比学习中,存在着正样本、负样本、对比损失等概念。其中,正样本表示与当前样本相关的样本,负样本则是与当前样本无关的样本。这里以一个非常经典的对比学习框架 SimCLR 为例,SimCLR 构造正样本的方式就是利用数据增广(Data Augmentation)方式,例如随机缩放、随机裁剪、添加高斯噪声等等方式得到的样本就是原来图片的正样本,因为这个样本可以看作是原样本的不同视角下观察的结果。对比损失的形式不只一种,它们的目标都是将正样本对的距离缩小、负样本对的距离增大。
下面是 CLIP 实现的伪代码:
# image_encoder - ResNet or Vision Transformer
# text_encoder - CBOW or Text Transformer
# I[n, h, w, c] - minibatch of aligned images
# T[n, l] - minibatch of aligned texts
# W_i[d_i, d_e] - learned proj of image to embed
# W_t[d_t, d_e] - learned proj of text to embed
# t - learned temperature parameter
# extract feature representations of each modality
I_f = image_encoder(I) # [n, d_i]
T_f = text_encoder(T) # [n, d_t]
# joint multimodal embedding [n, d_e]
I_e = l2_normalize(np.dot(I_f, W_i), axis=1)
T_e = l2_normalize(np.dot(T_f, W_t), axis=1)
# scaled pairwise cosine similarities [n, n]
logits = np.dot(I_e, T_e.T) * np.exp(t)
# symmetric loss function
labels = np.arange(n)
loss_i = cross_entropy_loss(logits, labels, axis=0)
loss_t = cross_entropy_loss(logits, labels, axis=1)
loss = (loss_i + loss_t)/2
代码解释如下:
- 将图像和文本进行编码,得到图像和文本的特征向量。
- 将特征向量线性投影,对齐特征维度。
- 计算它们之间的余弦相似度。
- 计算对比损失。
对于模型结构的选择,作者尝试了不同的模型,表现最好的是 Transformer 结构,对应的视觉编码器是 ViT、文本编码器是 BERT。
参考
[1] A. Radford et al., “Learning Transferable Visual Models From Natural Language Supervision,” Feb. 26, 2021, arXiv: arXiv:2103.00020. doi: 10.48550/arXiv.2103.00020.
[2] OpenAI. “CLIP”. Github 2020. [Online]. Available: https://github.com/OpenAI/CLIP
[3] T. Chen, S. Kornblith, M. Norouzi, and G. Hinton, “A Simple Framework for Contrastive Learning of Visual Representations,” Jul. 01, 2020, arXiv: arXiv:2002.05709. doi: 10.48550/arXiv.2002.05709.
[4] 李沐. “CLIP 论文逐段精读【论文精读】”. Bilibili 2022. [Online]. Available: https://www.bilibili.com/video/BV1SL4y1s7LQ/?spm_id_from=333.337.search-card.all.click&vd_source=c8a32a5a667964d5f1068d38d6182813
文档信息
- 本文作者:Ziyang Fan
- 本文链接:https://fanziyang-v.github.io/2025/03/22/clip/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)